PhD Projects¶
Below are a few PhD projects in my areas of interest. All projects require strong object-oriented design and development skills.
Domain-Specific Modelling in Web-Based IDEs¶
Integrated development environments (e.g. Eclipse, IntelliJ, Visual Studio) have been traditionally desktop applications. Nowadays, there is a growing trend for browser-based IDEs (e.g. Microsoft's vscode.dev, GitHub CodeSpaces, Gitpod, Eclipse Theia) that provide rich support for software development (e.g. code assistance, error highlighting/linting, quick fixes) but require no local software installation and configuration. While some frameworks have started emerging that enable the development of textual/graphical domain-specific modelling languages on top of web-based IDEs (e.g. Eclipse GLSP, Sirius Web, Langium), they are still at early stages of development and interoperability among them is severely restricted.
There is a lot of appetite in industry for domain-specific modelling and model-driven engineering solutions on top of web-based IDEs, but the tooling is not up to scratch yet, and there is little expertise available to meet this demand. A PhD in this area could propose processes and mechanisms for supporting different aspects of domain-specific modelling (e.g. multi-view graphical modelling, model validation and transformation), considering opportunities and challenges presented by web-based IDEs.
Collaborative Editing and Versioning of Graphical Models¶
The aim of this project is to investigate how state-of-the-art web-based graphical modelling frameworks such as Sirius Web and GLSP can be extended with support for resilient real-time (i.e. Google Docs-like) collaborative modelling, and how real-time collaborative model editing can be seamlessly combined with versioning in Git-like repositories.
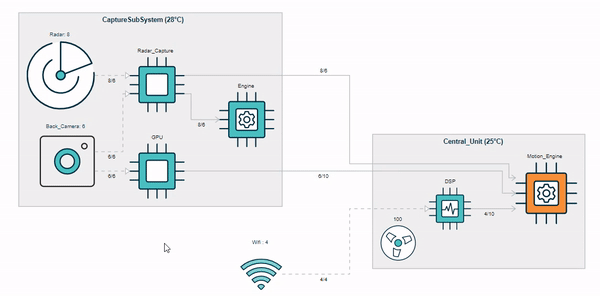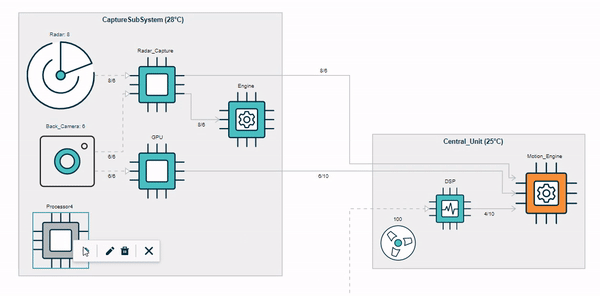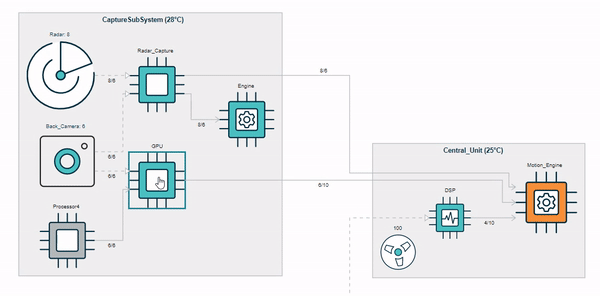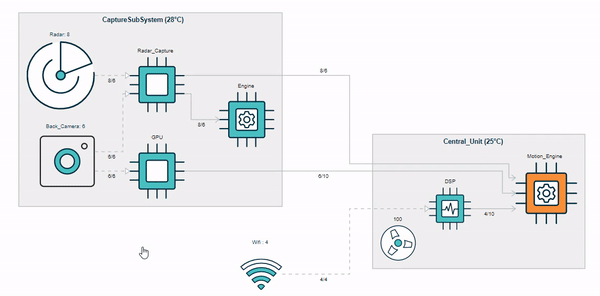
Traceable and Partially-Editable Model Views¶
Picto [1] is a tool for visualising models via model-to-text transformation to SVG/HTML. In the example below, a risk model (top right) is transformed into three HTML-based views ("High", "Medium", "Low"), that visualise risks with respective likelihood/severity in the model.

Currently, views in Picto are read-only and there is little support for traceability between the model and the views. The aim of the project is to extend Picto with support for partially-editable views (e.g. editing the title of the first risk in the view within Picto should update the respective risk in the model) and for tracing view elements back to their respective model elements (e.g. ctrl+click on the first yellow cell of the view should take the user to the l attribute in line 6 of the model. The main challenge is to detect which parts of the generated views have been generated from which model elements by capturing and analysing traceability information provided by the model-to-text transformation engine, and to decide which edits in generated views can be unambiguously propagated to the source model.
Flexible Textual Domain-Specific Modelling¶
Generic textual syntaxes for domain-specific models, such as HUTN and ESON, and bespoke syntaxes developed with frameworks such as Xtext, enable models to be created and edited using text instead of diagrams. However, they are syntactically rigid and their parsers fall over when they encounter even minor naming deviations.
The aim of this project is to further an existing line of work on an alternative, flexible, XML/YAML-based model persistence format (Flexmi) (see example below) by contributing facilities such as content assistance (code completion), refactoring, and reference visualisation and navigation and/or by exploring other options (e.g. Markdown) for developing similar flexible model representation formats.
<?nsuri psl?>
<project title="ACME">
<person name="Alice" :var="alice"/>
<person name="Bob"/>
<task title="Analysis" start="1" dur="3">
<effort person="Alice"/>
</task>
<task title="Design" start="4" dur="6" :var="design">
<effort person="Bob"/>
</task>
<task title="Implementation" :start="design.start+design.duration+1" dur="3">
<effort person="Bob" perc="50"/>
<effort :person="alice" perc="50"/>
</task>
</project>
Reactive Code Generation from Modular Software Models¶
In a model-based software development environment, code generators are used to transform software models (e.g. UML class diagrams, Simulink control models) to working software code. As models grow in size, re-running a code generator in its entirety for every small change in the software model is wasteful and can significantly slow down the software development process. To address this problem, previous work [1, 2] has proposed techniques for incremental/reactive execution of model management programs. To achieve incremental execution, the code generation engine needs be able to tell what changed in the model (at a very fine and precise level), which can be quite expensive in its own right and can quickly become a bottleneck for large monolithic models.
The aim of this project is to propose new/adapted reactive execution techniques that are optimised for modular models split over multiple inter-connected model fragments/files [3, 4], and exploit facilities present in contemporary software development workstations (e.g. multi-core processors, SSD disks).
Large Language Models for Software Model Management¶
Large Language Models (LLMs), such as GPT-4 and Mistral, have demonstrated impressive abilities in natural language processing tasks such as language translation, text summarization, and question answering. The aim of this project is to investigate the degree to which LLMs can be used to query and modify/transform structured software models (e.g. domain-specific, UML, Simulink models) using instructions in natural language. The project will involve proposing and evaluating the efficacy of different LLM-targeted encoding schemes for models, and appropriate prompt engineering techniques, including the use of advanced LLM mechanisms such as functions.