Testing the November Alfa Tango Oscar Spelling Alphabet (2.1*)
Alistair D N Edwards
Department of Computer Science
University of York
Heslington
York
UK
YO10 5GH
Abstract
Spelling alphabets are used as a means of ensuring unambiguous voice transmission of letters.
The best-known example is the Nato alphabet, Alfa, Bravo, Charlie…
A necessary property of any such alphabet is that the words should be audibly distinguishable.
This paper investigates a method for assessing the distinctiveness of each pair of letters.
This is based upon expressing the phonetic pronunciation of the words (using the International Phonetic Alphabet)
and then measuring the degree of similarity between the words.
This is done by calculating the edit distance between the words, which is essentially the number of edit operations required to transform one word into the other.
This paper outlines the history of the development of the Nato alphabet and applies the edit-distance method to a number of candidate alphabets.
The main conclusions are that the Nato alphabet is quite a good one, but perhaps not as good as it might be.
That is, at least, according to the method, but since the results of the analyses are not in close agreement with empirical tests in the literature,
it may be a bit useless.
1. Introduction
Voice-based communications can suffer from intelligibility problems.
Where the elimination of ambiguity is important, then words may be spelled out.
Verbally spelling, though, can itself be unreliable;
letters spoken in the conventional way ('Ay', 'Bee', 'Sea' etc) can sound similar and be mis-heard and confused.
One approach to mitigating this is the use of spelling alphabets, whereby longer words are used to represent the letters (e.g. 'Alpha', 'Bravo', 'Charlie' - see below)1.
Where the identity of a particular word or its spelling is important in the communication, it can be spelled out using this alphabet
(e.g. 'Echo, Delta, Whiskey, Alpha, Romeo, Delta, Sierra').
There are also instances when letters not words need to be communicated, and often it is vital that there is no ambiguity.
For instance, a callsign may just be letters, or a car registration may need to be passed on.
There are a number of properties that are desirable in a spelling alphabet, including:
The words should be audibly as different from each other as possible.
The words should be long (i.e. longer than the monosyllabic 'Ay Bee Sea'), but not so long as to slow down the communication any more than necessary.
They should be easy to remember, with an obvious mapping to the letter they represent.
This paper concentrates on property (1), above.
Can we measure how well different letters can be distinguished?
The approach taken has been to convert the words into a phonetic form and then to measure the degree of difference between each of the pairs of words.
The paper investigates a number of spelling alphabets, with particular interest in the Nato2 Phonetic Alphabet, which is the international standard for this purpose.
I could write this paper to a publishable standard – and then perhaps try to get it published.
However, I cannot be bothered;
I cannot be bothered to click much further than Wikipedia for references, for instance.
Nevertheless, I hope readers find it interesting and useful.
2. Background
2.1 Letters
Letters of the Latin alphabet have common, onomatopoeic names, 'Ay', 'Bee', 'Sea' etc.
These have an obvious (but not necessarily direct) mapping to their phonetic values in written text.
They are short sounds, which is appropriate for most purposes.
However, they can sound quite similar.
Take, for instance, the vowels.
The nature of a vowel is that it is a sound made with an open, unconstricted vocal tract and therefore their letter values
('Ay', 'Ee', 'Eye', 'Oh' and 'Yew') sound quite similar.
Indeed, they are to some extent inter-changeable.
The common greeting can be written (and pronounced as) 'hello', 'hallo', 'hullo' and even 'hillo'.
One of the obvious variations in different spoken accents is in the pronunciation of the vowels.
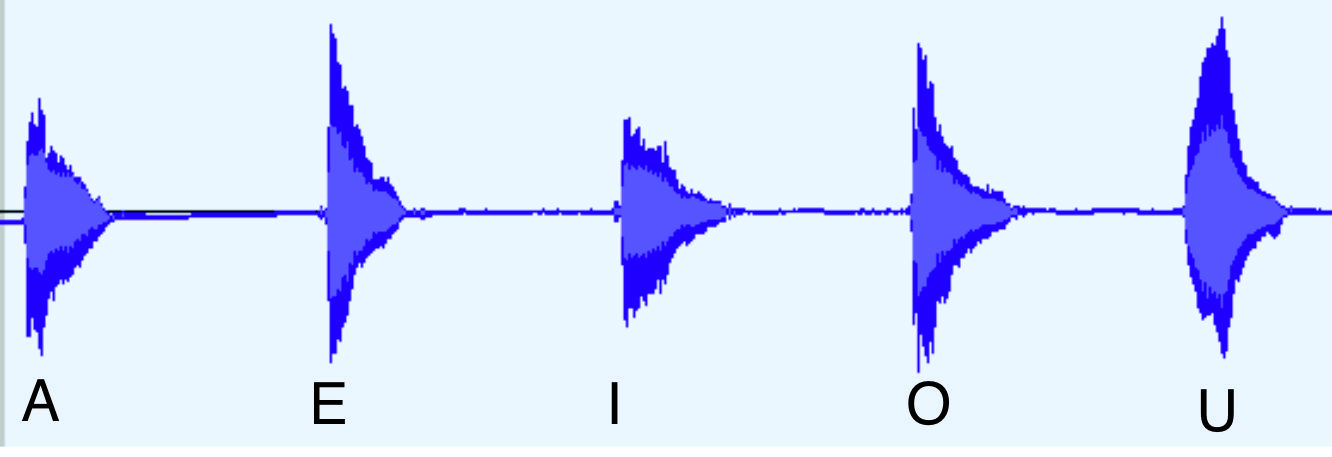
At an acoustic level the waveforms of the vowels are quite similar, as shown in Figure 1.
Figure 1.
Waveforms of the vowels.
Note that their outlines are quite similar.
Click on the image if you want to hear the vowels.
Notice the attack portions of the waveforms
(the onset of the sound, on the left)
are quite similar and abrupt, while the decay portions
(beyond the maxima)
are also similar, triangular shapes.
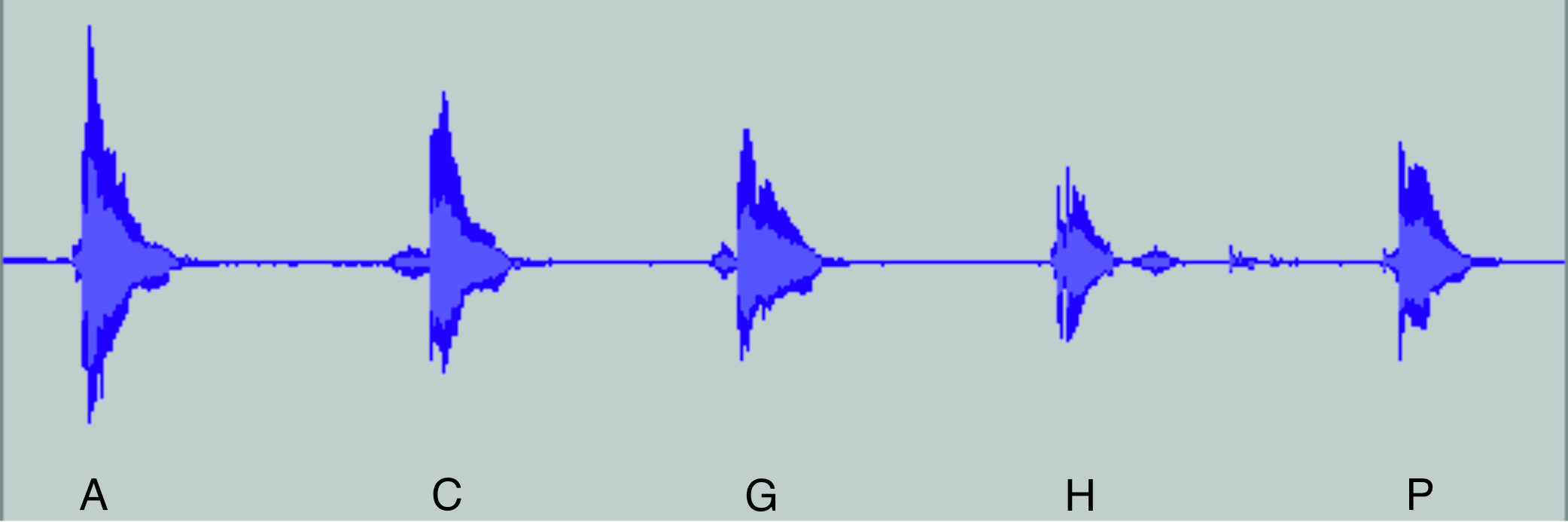
Contrast with the waveforms of the letters A, C, G, H, P in Figure 2.
Figure 2.
Waveforms of the letters A, C, G, H and P.
It is apparent how different the shapes of these waveforms are, and hence they are more easily distinguished audibly.
It should now be apparent why the names of the letters are easily confused audibly.
In everyday communication – particularly face-to-face – this is rarely a problem.
Indeed, face-to-face dialogue is not purely auditory, there is a visual component.
Even hearing people can and do use a degree of lip-reading.
Whereas the sounds of the letters B and V might easily be confused, if the listener is watching the lips of the speaker they are quite likely to see the difference.
When speech takes place via technology (telephone, radio etc) then it does become purely auditory and confusions may arise, hence the need for spelling alphabets.
2.2 Spelling alphabets
With the advent of speech technologies, first the (wired) telephone and then later what was known as radiotelephony, the need for spelling alphabets became apparent.
These could be informal, even made up spontaneously by the speaker, but organizations also adopted standardized alphabets.
So it was that the International Civil Aviation Organization (ICAO) published a report in 1959 (ICAO, 19593) which counted and lists no fewer than 203 different spelling alphabets.
That report is a comprehensive read for anyone interested in the history of the development of these alphabets.
It also describes how the ICAO alphabet was designed, using experiments based on recordings of speech in noise to measure intelligiblity and ambiguity.
ICAO (1959) is entitled The evolution and rationale of the ICAO word-spelling alphabet,
and traces the development which led to the recommendation of the ICAO alphabet as an optimum list for international communications (p.ii).
The paper states that the first International Telecommunication Union alphabet was adopted in 1926. (Figure ITU1).
It is interesting that these words are all place names.
The report states, though, that '[O]perating experience has indicated that the words were unsuitable because they were unusual in everyday language and because they lacked desirable phonetic qualities' (p.9).
It goes on to suggest that there was a new era of development in international alphabets with the entrance of the United States into World War II.
Then a number of alphabets were examined.
Many were found wanting.
'The results showed that many of the words in the military lists had a low level of intelligibility, but that most of the deficiencies could be remedied by the judicious selection of words from the commercial codes and those tested by the laboratory.' (p.9)
This resulted in the National Defense Reseach Committee (NDRC) list.
This is listed in ICAO (1959), but unfortunately the quality of the published scan of that paper is so low that it is unintelligible.
Desirable properties for a spelling alphabet were listed in the Introduction, above, and we can look at them in more detail and extend them here.
1. The words should be audibly as different from each other as possible.
That is the main topic of this paper, so read on.
In radiotelephony it is also important that they should not resemble any other standard words and phrases, such as 'Roger', 'Over' and 'Negative' –
and certainly not 'Mayday' –
nor any of the digits.
(See also Section 5, below.)
There is a further requirement that does not seem to be mentioned in any of the papers.
The use of a word as a spelling alphabet should not be confused with that word being used in its everyday meaning.
2. The words should be long, but not so long as to slow down the communication any more than necessary.
The essential problem with the normal letter sounds is a lack of redundancy.
If a longer sound is used then if part of it is unheard or masked it may still be identified.
For instance, in the Nato alphabet that we will be investigating in more detail below,
if the initial G sound in 'Golf' is missed or misheard there is no other letter which ends in the 'olf' sound with which it could be confused.
Words may even have more than one syllable (e.g. 'Foxtrot').
To choose even longer words introduces even more redundancy, but may also slow down communication.
3. They should be easy to remember, with an obvious mapping to the letter they represent.
This is generally achieved by choosing words which start with the letter that they represent.
4. They should be pronounceable to speakers whose first language is not English.
English is the official language of radio communication and thus any spelling alphabet will be used by people whose native language is not English.
While pronunciations may vary (see Accents) the words should not be difficult for non-English-speakers to say.
The ICAO Spelling Alphabet (precursor to the Nato Alphabet) was tested with regard to the three main languages used in Nato member countries: English, French and Spanish.
ICAO (1959) suggests that for internationalization each word in the alphabet should be 'live' in each of the three working languages, although it is not clear what 'live' means here.
5. They should not have any meaning that might be found offensive.
Further to point (4), the words should not be suggestive of any offensive meanings in any common language.
The choice of phonetically distinguishable words is not easy because of the number of combinations.
Nato memo suggests
It is known that [the ICAO spelling alphabet] has been prepared only after the most exhaustive tests on a scientific basis by several nations.
One of the firmest conclusions reached was that it was not practical to make an isolated change to clear confusion between one pair of letters.
To change one word involves reconsideration of the whole alphabet to ensure that the change proposed to clear one confusion does not itself introduce others.
The problem is not unlike that of pushing a dent out of a child's celluloid ball – even a successful push leaves a small dent in another place.
This paper traces the history of some of the development of spelling alphabets, testing them along the way.
It will be seen that the ICAO was responsible for the evolution of the standard alphabet, which was adopted as the standard alphabet for Nato (the so-called Nato Phonetic Alphabet) in 1955.
2.3 Phonetics
Phonetics is concerned with the sounds of words.
While there are 26 letters in the Latin alphabet, there are a lot more sounds than that in English words.
The basic unit of sound is the phoneme.
A simple definition of a phoneme is a unit of a word which it if were replaced by another phoneme the meaning of the word would be changed.
For instance, if one replaces the 't' sound at the beginning of the word 'toffee' with a 'k' sound then the word would become 'coffee'.
It is generally accepted that there are 44 phonemes in English.
It is evident that the 26 letters of the alphabet are insufficient to unambiguously represent 44 phonemic sounds.
This is partly accounted for by the use of pairs of letters to represent additional sounds.
Examples are 'sh', 'ee', and 'th'.
There are also other spelling conventions which give clues to pronunciation.
However, English is notoriously unphonetic and irregular in its rules4.
The Latin alphabet is thus quite inadequate to unambiguously represent the sounds of all (English) words.
Futhermore there are many other phonemes which are found in languages other than English.
The International Phonetic Alphabet (IPA) has been devised with the objective of containing one symbol to represent every phoneme in natural languages.
There are 107 segmental letters in the IPA, and symbols had to be invented to represent that number of sounds.
Many of the symbols resemble letters in conventional alphabets (e.g. a, b and c) – and variations thereon (such as upside-down letters ɐ, ə, ʌ).
A guide to IPA symbol pronunciation can be found in Appendix A.
In addition to the segmental letters there are suprasegmentals.
These can mark stress (e.g. ˈ to mark the primary stress).
The symbol ː indicates lengthening of the previous letter sound, and syllable boundaries can also be marked.
Stress is considered important in the use of spelling alphabets.
For instance ICAO (2001) spells out the expected stress patterns
(e.g. AL FAH, HO TELL, JEW LEE ETT).
However, the stress markings on the IPA string cannot be considered to be part of the spelling, as such.
For one thing they do not affect the sound of the pronunciation.
Secondly, their placement cannot be fairly measured using edit distances, as described below.
It is thus possible to translate (the sounds of) any word into its (IPA) phonetic representation.
Most of the IPA translations used in this research were provided by the website ToPhonetics.com.
2.4 Edit distances
A collection of characters (such as a word) can be referred to in the abstract as a string.
It is possible to calculate the degree of difference between two strings, by measuring the edit distance.
The edit distance between two strings is really a count of the number of single-character editing operations (insertions, deletions or substitutions) that would be required to transform one string into the other.
Taking the earlier example, the edit distance between toffee and coffee is 1, since it takes just one substitution to make that transformation.
The edit distance between toffee and free is 3, that is 2 deletions + 1 substitution.
As described below, the basis of this work was measuring the edit distances between phonetic representations of spelling alphabet letters.
In this case the measure is the Levenshtein Distance.
(Figure 3).
This measure was chosen because it works for strings of different lengths.
function LevenshteinDistance(char s[1..m], char t[1..n]):
// for all i and j, d[i,j] will hold the Levenshtein distance between
// the first i characters of s and the first j characters of t
declare int d[0..m, 0..n]
set each element in d to zero
// source prefixes can be transformed into empty string by
// dropping all characters
for i from 1 to m:
d[i, 0] := i
// target prefixes can be reached from empty source prefix
// by inserting every character
for j from 1 to n:
d[0, j] := j
for j from 1 to n:
for i from 1 to m:
if s[i] = t[j]:
substitutionCost := 0
else:
substitutionCost := 1
d[i, j] := minimum(d[i-1, j] + 1, // deletion
d[i, j-1] + 1, // insertion
d[i-1, j-1] + substitutionCost) // substitution
return d[m, n]
Figure 3 Calculating the Levenshtein Distance
This is pseudo-code not in any implemented programming language and taken directly from Wikipedia.
It would not be appropriate to include stress marks in the measurement of the edit distance because
the stress marks on two different words may be very separated (on the first syllable, as is the default in English, but on the last syllable for another);
Including the edit distance between these marks in the overall edit distance would give a distorted and artificially great overall edit distance.
A longer explanation of edit distances can be found in Appendix B,
and the software to measure the edit differences was written in C and the source code for this is
available on-line.
2.5 Accents
The precise sound of any spoken word depends on the accent of the speaker.
By extension the translation of an English spelling to an IPA representation will represent an assumption as to the accent of the 'speaker'.
The website toPhonetics.com offers two accents: 'American' and 'British'.
It is, of course, fallacious to suggest that there is just one American and one British accent6,
but given that most of the development of the ICAO and subsequent Nato alphabets took place in the USA, the American accent has been used in most of these experiments.
However, given that the alphabets are meant to be international it is not only the accents of English-speaking Americans and Britons that are to be accommodated.
ICAO (1959) refers to the principal non-English-language-speakers to be accommodated as French and Spanish.
However, given that English is the official language of radiotelephony, the alphabet ought to be robust to speakers of practically every spoken language.
2.6 X-Words
One problem with English spelling words is that there are very few which start with the letter X.
Furthermore, for most of those that do it is sounded as a Z.
As we will see, many of the alphabets get around this by using the word X-ray.
Having filled in all this background, we can go on to explain this little set of experiments.
3. Method
The idea behind this study was to take words from spelling alphabets, translate them into phonetic representations, to measure the edit distances between each pair of letters and then to identify where the weaknesses were.
Specifically, it was interesting to see whether this analysis would support any suggestion that the Nato alphabet is optimal.
Given that the more recent alphabets (including the Nato one) have been developed on the basis of empirical experiments it is also interesting to evaluate the method:
do the results of these analyses concur with the results of those experiments?
As suggested above, the online toPhonetics tool was used to convert English spellings of the spelling alphabet letters to IPA.
Then the edit distances between each pair of letters was calculated6.
Some aspects of the IPA translation were ignored.
3.1 Metrics
The edit distance indicates the degree of similarity between two strings:
a short edit distance implies that the strings are more similar, so in this context a greater distance is a desirable property.
For instance, if the edit distance is as low as 1, then confusing just one phoneme for another could cause the confusion of the two words.
It would be desirable to come up with a simple metric, perhaps a single number, by which whole different alphabets could be compared.
The median edit distance between each of the pairs of letters is such a number, but it should be used with care with regard to outliers.
That is to say, for instance, that an alphabet with a large number of short edit distances (perhaps a lot of 1s) might also have a lot of long distances (e.g. 9s),
with the result that its overall median is quite reasonable.
In other words, this would obscure the prevalence of short distances.
The pairs with distances equal to 9 would be good, hard to confuse, but there might be many instances of the low-scoring pairs being confused.
It is appropriate, therefore, to concentrate on the low-scoring pairs.
A simple rule-of-thumb would be to reject any alphabet in which any pairs have a distance of 1.
One might also be cautious of any with large numbers of short distances (perhaps 2).
The modal average for any letter will also give an indication of the robustness of that particular letter.
4. The Experiments
As noted elsewhere, there has been a plethora of spelling alphabets.
It was decided, therefore, to pick a small number of them that seem to have been historically significant, leading up to the adoption of the Nato alphabet, to see how they evolved.
4.1 ITU
As mentioned earlier, the first international alphabet was adopted by the International Telecommunications Union (ITU, See Figure 4).
Cells coloured green are those with the maximum length in this table (10 in this case) and the red
ones are those with the minimum length in the table (5).
These are the ones which might be cause for concern as the ones most likely to be confused.
In this case, though, a minimum distance of 5 is not really a concern;
we will see many examples below of alphabets with shorter minima.
It is notable, but not surprising, that the words are quite long.
Xanthippe was the wife of Socrates.
It was probably a poor choice of word since few people would know how to pronounce it (zænˈθɪpi) and it starts with a z sound.
(See X-Words).
If you hover over a cell in the table, you can see its column and row identity.
The statistics suggests that this alphabet was quite robust.
However, it was not adopted by the ICAO.
ICAO (1959) states (p.9) that,
'[O]perating experience has indicated that the words were unsuitable because they were unusual in everyday language and because they lacked desirable phonetic qualities'.
It does not state what those (lacking) phonetic qualities are.
This is a shame, because the words are long and multisyllabic (mean length of the Latin spelling is 7.58 and the IPA transcription is 7.77), and hence have a lot of redundancy, so that one might assume they are well distinguished,
and this seems to be confirmed in Figure 4.
The maximum length is 10 and as many as 18 pairs have this score (marked in green in the Figure), implying pairs which are most unlikely to be confused.
At the same time the minimum length is as large as 5 and there are only six pairs that close.
The mention of being 'unusual in everyday language' is probably important.
All of the words are place names, and it seems likely that they might be pronounced quite differently by speakers of different first languages.
4.2 RAF
It is evident that a lot of the early spelling alphabets were quite ad hoc, not devised with the scientific approach that we will see
below
went into the development of what became the Nato alphabet.
The Royal Air Force (RAF) used at least two different alphabets,
and they were different from those used by other British forces.
The alphabet used by the Royal Air Force in 1921-42 was as in Figure 5.
Overall median = 5. Largest distance = 6 (84 occurrences). Shortest distance = 2 (34 occurrences)
Evidently this was quite a poor alphabet.
There are no fewer than eleven pairs with an edit distance of just 2.
It is notable that the words are short: the mean number of letters in the English spellings is 4.90 and their IPA spellings 4.12.
Shorter words have lower redundancy so it is no surprise that there are a large number of potential clashes.
4.3 ICAO
According to ICAO (1959), during World War II there was some of the almost-inevitable nationalistic and political wrangling over the adoption of a standard international alphabet.
'[T]here still remained several words on which neither the US nor the British side would yield.
Therefore, the Generals and Admirals went down taking first a US and then a UK preference to complete the list and get on with the war.' (p. 10).
With the end of the war, though, there was the realization of the need for a standard alphabet for use in aviation.
The International Civil Aviation Organization (ICAO) was established in 1944 and in 1946 it agreed on an international alphabet, the Combined Services Alphabet.
The report is inconsistent regarding dates, but it seems that the agreed alphabet was that shown in Figure 6.
The words in this alphabet are shorter than the ITU alphabet (mean IPA string length 4.42 versus 7.77) so there is less redundancy.
Consequently the maximum distance of 6 is much less than the 10 for the ITU and the overall mean of 5.06 is much less than the 8.32 for the ITU alphabet.
Hence, in terms of confusibility this alphabet is somewhat worse than for ITU.
Overall median = 5. Largest distance = 6 (106 occurrences). Shortest distance = 2 (8 occurrences)
Internationalization remained a problem.
Spanish-speaking representatives stated that this alphabet was not suitable for Spanish speakers.
A separate alphabet was thus agreed for this group.
Unfortunately, due to the poor quality scan of ICAO (1959) the Spanish alphabet is illegible.
It is notable that some of the letter names are spelt in an unconventional way.
Alfa is an example, and presumably this is to overcome any ambiguity in the pronunciation;
would non-Native English speakers understand the conventional pronunciation of 'ph' in 'Alpha'?7
In the next few years Prof Paul Vinay was commissioned to develop an alphabet, 'according to logical linguistic principles to be acceptable to international users' (ICAO, 1959, p.11).
This resulted in the alphabet in Figure 7.
Figure 7.
Edit distances for all of the pairs of letters in the ICAO 1949 alphabet.
Overall median = 6. Largest distance = 8 (28 occurrences). Shortest distance = 2 (4 occurrences)
Also shown is data from Figure 2 of ICAO (1959),
which recorded the number of times a letter was heard when a letter was spoken (against noise).
In most instances it should be expected that when (say) Echo was spoken then Echo was heard,
but (for instance) in fact in 32 cases the listener thought they had heard Hotel.
The paper also gives an 'articulation count', the percentage of times that the correct letter was heard.
Note that due to the poor quality of the scan of the paper some of the numbers in this column are illegible and have been omitted here,
and some are hard to read so the best guess as to their value has been given.
That a letter should only be correctly heard as little as 66% or less of the times it has been spoken would seem to be a matter for concern,
so values lower than that are highlighted in red.
It also gives a 'confusability score', which is the number of times the word is heard when another is spoke.
In the paper a number of cells were circled as causing concern, if their value was above a chosen but arbitrary value,
and the corresponding cells are grey in this diagram.
A count of the number of such cells, 'Circles' is given here, because the larger this number the more fragile that letter is.
Cells with the largest Circles values (3) are highlighted in red.
Given the motivation that the alphabet should be truly international, it made sense to see whether using the 'British' accent of toPhonetics made any difference.
(Figure 8).
Figure 8. Edit distances of the ICAO alphabet
(Figure 7) but when pronounced with a 'British' accent.
Overall median = 5. Largest distance = 8 (24 occurrences). Shortest distance = 2 (8 occurrences)
There are no substantial differences from the 'American' version.
It is evident that the change of accent has not had a large effect, but there are a couple of interesting differences.
Julietta shows a higher degree of robustness in the British accent;
it has a maximum distance (8) from 19 other letters.
The IPA representation is the same as for the American accent, so it is the pronunciation of the other letters which varies.
Also in the British version there are two more pairs with the minimum difference: Beta-Lima, and Delta-Nectar.
These are accounted for by differences in the IPA spellings, which do appear to reflect differences in pronuciation in British English,
specifically of 'Beta' (bitə versus beɪtə) and 'Nectar' (nɛktə versus nɛktər).
Hereafter in this paper the American accent (or toPhonetic's idea thereof) is used in all the examples.
Comparison with ICAO Experiments
There were extensive experiments carried out to compare the ICAO 1946 alphabet with the ICAO alphabet which concluded that the ICAO was superior.
Nevertheless, efforts were expended to attempt to improve he ICAO alphabet.
One of the objectives was to eliminate the 'confusable' words.
Figure 2 of ICAO (1959) shows how each letter word was spoken a number of times – with noise and the letter that the listener thought they had heard was counted.
There are two problems with this figure.
One is that it is not stated how many times each letter was spoken.
The second problem is the poor quality of the scan of the paper, so that some of the numbers in this matrix are illegible.
In other words, were it not for the latter problem it would be possible to count the former number.
An 'articulation score' is given, which is the percentage of times that the word was correctly identified,
and a 'confusability score', which is the number of times the word is heard when another is spoken.
The ideal is thus a word with a high articulation score and a low confusability score.
Note that unlike the figures in this paper, this matrix is not symmetric.
This is because it distinguishes between times when (for instance) the word Echo was spoken, but Hotel heard,
and the number of times that Hotel was spoken and Echo heard.
This contrasts with the phonetic scores used in this paper, where the edit distance between
Echo and Hotel is the same as that between Hotel and Echo.
A number of cells in the table are circled which indicate clashes of concern, although the value chosen as a matter for concern is said to be 'arbitrary'.
The corresponding cells in Figure 7 are highlighted in grey and the number of grey cells for each letter given ('Circled').
Also transferred are the articulation score and the confusability score.
There are a few points to note about this experiment and these results.
Firstly, it is probably worthwhile quoting what the paper says about the method.
Speakers representing the NATO nationalities spoke a number of lists of random three-letter code groups using the two alphabets to be investigated, and tape recordings were made of these lists.
Two sets of list: were prepared, one for training purposes to acquaint the listeners with the words of each alphabet, noise interference, and foreign dialects of the speakers, while another set was made for the actual test condition.
After approximately twelve hours of listening practice to ensure complete familiarity with both alphabets,
the experimental subjects, foreign and American, listened to the
test lists under three prescribed conditions of noise interference.
Two types of noise generators were employed to introduce interference in the listening
lines, end the speech level was attenuated to achieve progressively more difficult reception conditions.
The resultant scores were compared end analyzed for differences.
There are a number of points to notice in this description of the method, often relating to omissions and unclear descriptions.
Notably:
How many Nato nationalities were represented in the speakers?
Presumably native speakers of English (American and/or British?), French and Spanish.
Equal numbers of each?
How many participants took part?
How many sets of letters did they hear in the study?
Twelve hours of 'practice' is mentioned, but was that followed by a similar duration for the second list, the experimental condition?
How were those 12 hours distributed?
Presumably there were rest periods – otherwise there would surely have been a fatigue effect.
Three different 'conditions of noise interference' are mentioned,
as well as two types of noise generator –
and attenuation of the speech level.
In other words, the conditions were (very) different in different cases.
There were potentially 6 different noise conditions and an unstated number of levels of speech –
plus the number of different accents of the speakers.
Presumably this was intended to simulate the variety of difficult conditions that might be encountered in the field,
but it does raise a lot of questions.
Presumably the results under all of the conditions have been pooled.
Given the above assumptions that may be reasonable, but it might have been informative to see separate analyses of the different conditions;
not the least this might have given some justification of the choice of conditions used in the experiments.
Did every participant hear examples under the same sets of conditions?
A 'number of lists of random three letter code groups'
What number (as above)?
Although the lists were random, did each participant hear the same lists?
Why three-letter groups?
(Might there have been proximity effects, e.g. the word Alfa is clearer when heard after Foxtrot than after Beta?)
Minimal statistics are presented
This exacerbates some of the above criticisms.
For instance, not knowing how many times letters were tested it is not possible to make comparisons.
One comparison it was possible to make is to calculate the mean Articulation Score, but this does not appear in the paper.
There is mention that, 'The performance is statistically significant at a confidence level of one-tenth of one per cent'. (op cit. p.12)
However, no details are provided as to how this was measured and hence what 0.1% means.
Given that our results seem at variance with those in the paper,
the above list might be seen as criticisms, along the lines of 'their method was poor, so ours was better', but that is not the intention.
On the contrary, given the divergence in results it would be good to know more details of their method so that we can see in what ways what ICAO was measuring was different from what we have been measuring and then we could see (or at least hypothesize) as to why the results are different.
Putting these questions aside, the pairs identified as problematic are shown in Table 1, along with their edit distances.
Letter spoken
Letter heard
Letter spoken
Letter heard
Edit distance
1
Echo
Hotel
4
2
Foxtrot
Oscar
7
3
Hotel
Coca
4
4
Julietta
Union
Union
Julietta
6
5
Julietta
Zulu
Zulu
Julietta
5
6
Lima
Union
Union
Lima
5
7
Metro
Echo
6
8
Nectar
5
9
eXtra
5
10
Nectar
Lima
5
11
eXtra
4
12
Union
Zulu
5
13
Victor
eXtra
5
14
eXtra
Echo
4
Table 1. Letter pairs which were circled in Figure 2 of ICAO (1959),
along with their edit distances.
Notice that some pairs are symmetrical (e.g. both Julietta/Union and Union/Julietta were circled.
The letters which were subsequently replaced are highlighted in grey.
It was decided to replace Coca, Metro and eXtra with Charlie, Mike and X-ray.
The latter three had shown 'above-average' performance in earlier tests.
The report says of the first three that they showed below-average performance and,
'in the opinion of the project's foreign language consultant that they were phonemically adapted to Nato users' (ICAO, 1959, p.14).
No explanation as to why the latter three were selected for substitution is given, but they were replaced, as in Table 1
It is notable in this figure that only one of the letters with a short edit distance is in this list.
That is to say that Coca has an edit distance of 2 with Echo.
Otherwise none of the identified letters seems to have any problems of small edit distances.
There are no cells in Figure 7 which ought to be both grey and red.
This would seem to suggest that the phonetic edit distance method proposed in this paper is useless, but let's carry on anyway.
It may also have been thought that eXtra was not suitable since it breaks the convention of starting with the indicated letter (i.e. 'E', not 'X').
Noting the apparent problems with these letters, the next alphabet tested was as in Figure 9.
The substitutions were as in Table 2.
ICAO 1949
ICAO 1952
Coca
Charlie
Foxtrot
Football
Metro
Mike
Union
Uniform
eXtra
X-ray
Zulu
Zebra
Table 2
Substitutions made in refining the ICAO alphabet.
The edit distances for the revised alphabet are shown in Figure 9.
The first thing that is evident is that the minimum score is still 2;
the possible confusion between Coca and Echo has been eliminated by replacing Coca with Charlie.
The replacement of Foxtrot by Football seems less successful, the mode score of the former being 7 and the latter 5.
Conversely, the modal score for the new word Uniform is 7, rather better than Union (5).
The modal scores for Zulu and Zebra are the same (4), although Zebra has a minimum score of 2, with Sierra.
Figure 9 Edit distances for the revised ICAO alphabet.
Overall median = 5. Largest distance = 7 (30 occurrences). Shortest distance = 2 (8 occurrences)
Again data is also shown from the ICAO Report (Figure 3).
Notice that no letter has more than one greyed cell and none of the articulation scores is below 66.6, indeed the smallest is 81.6.
There were eight occurrences (double-counted) of the minimum score (2):
Golf,Papa
Lima,Mike
Nectar,Victor
Sierra, Zebra
Apparently the British researchers also noted problems due to the similarities between Nectar and Victor.The next – and final – iteration substituted Foxtrot, November and Zulu,
as in Figure 10.
Whereas we suggested above that we might as well give up, our results being so different from those in the ICAO report,
a more realistic conclusion might be that there is little point in trying to compare our results with those in ICAO (1959).
It is evident that the two methods were measuring different things – because they have yielded very different results.
The problem is that, because of the paucity of detail in the ICAO paper, it is not clear what was being measured.
Let us assume that the ICAO meausures were valuable, and hence the Nato Alphabet is a good one, but that there is scope for supplementing such methods with the edit distance method presented herein, which might lead to even better alphabets.
(See below.)
5. Numerals
Evidently numbers are different from letters.
However, they may be spoken in the same context as letters, for instance in a callsign or car registration.
It is therefore important that they should also be distinguished from each other as well as from the letters.
There is no suggestion of using anything other than the normal number names, but there is a prescription as to how they should be pronounced.
Particularly the number 9, should not be pronounced as 'nine' but rather as 'niner'.
It is useful therefore, to also test the phonetic representation of the numbers with the letters.
It is notable that many of the research papers on this topic, such as ICAO (1959), do not mention the numbers.
Given the adption by Nato and the results below, this may be a matter of concern.
Edit distances for the Nato alphabet and the numerals are given in Figure 11.
Figure 11. Edit distances for the Nato alphabet including the numerals.
Overall median = 5. Largest distance = 9 (42 occurrences). Shortest distance = 2 (6 occurrences).
The minimum distance is again 2.
Nato (1955) notes a potential problem with figures, that Zero and Sierra sound quite similar8.
This is not evident from the above analysis, where the distance between the spellings is 5.
The memo suggests the solution to this is the use of the 'proword' 'Figures' before the use of numerals.
The apparent similarity of the numbers Two and Three, though, might be cause for concern.
(Note that the suggested pronunciation of the latter is as Tree).
Clearly to confuse two numbers could have catastrophic consequences, and a 'Figures' prefix would not prevent this.
Table 3
Shortest distances for the Nato alphabet including digits.
There are three instances of the (undesirable) minimum distance of 2 (compared with two instances when digits are not included).
Given that there are so many potential confusions with the digits, it is worthwhile to look at the digits alone, and that is what we see in
Figure 12.
It is evident that the -er suffix on Nine is effective (mode=5, the maximum distance).
A cause for concern, though, is the short distance of 1 between Two and Three ('Tree').
It is interesting to see whether the suggested pronunciations are effective, so Figure 13 shows the distances for the digits with their normal pronunciation
(at least as 'pronounced' by toPhonetics.com.)
Nine is less distinct.
Its mode=4, and there is a distance of just 2 between it and Five.
The official pronunciations would appear to be effective.
Letter
0
1
2
3
4
5
6
7
8
9
zɪroʊ
wʌn
tu
tri
foʊər
faɪf
sɪks
sɛvən
eɪt
naɪnər
0
Zero
zɪroʊ
5
5
5
5
4
4
5
4
6
1
One
wʌn
5
3
3
5
4
4
5
3
5
2
Two
tu
5
3
2
5
4
4
5
3
6
3
Three
tri
5
3
2
5
4
4
5
3
6
4
Four
foʊər
5
5
5
5
4
5
4
5
6
5
Five
faɪf
4
4
4
4
4
4
5
4
4
6
Six
sɪks
4
4
4
4
5
4
4
3
6
7
Seven
sɛvən
5
5
5
5
4
5
4
5
5
8
Eight
eɪt
4
3
3
3
5
4
3
5
6
9
Nine
naɪnər
6
5
6
6
6
4
6
5
6
Mean
4.78
4.11
4.11
4.11
4.89
4.11
4.22
4.78
4.00
5.56
Mode
5
5
5
5
5
4
4
5
3
6
Figure 12
Distances for the digits, using the Nato recommended pronunciation.
The addition of the -er suffix on 9 is evidently effective, but the distance of just 1 between Two and Three ('Tree') is a cause for concern.
Overall median = 5. Largest distance = 9 (42 occurrences). Shortest distance = 2 (6 occurrences).
Figure 13
Edit distances for the digits, using their conventional pronunciation.
Overall median = 4. Largest distance = 5 (10 occurrences). Shortest distance = 2 (1 occurrence)
The numbers seem to represent something of a problem.
As argued above, it is most important that they should not be confused – certainly with each other, but also not with the letters.
Unlike the letters, though, it does not seem practical to use different (but more phonetically distinct) words for the numbers.
6. A better alphabet?
As noted earlier it seems as if Nato felt that their alphabet was 'good enough', perhaps an attitide of, 'If it ain't broke don't fix it'.
Yet it is apparent that there could be scope for improvement; a better alphabet might be devised.
Let us say it here, though, it is most unlikely that the Nato alphabet will ever be replaced, due to inertia.
We can make an analogy with the qwerty keyboard layout.
The origins of the layout are disputed (Kay, 2013), it is also controversial as to how efficient it is, but there is some evidence that it is
less effcient than alternative layouts, such as the Dvorak layout
(e.g. Neill, 1980).
However, there is general agreement that qwerty is unlikely to ever be superceded.
This is because people know the layout; they have invested in learning it.
To replace the layout with any other, even one that has been demonstrated – with practice – to be much more efficient, is simply not going to happen, because of that need to practise and adapt.
So it is with the Nato alphabet.
Suppose a much better, more robust alphabet were devised, operators would have to unlearn the old one.
Can you imagine a pilot trying to remember whether it is November or Nectar?
Think of the potential confusion during any transition from the Nato alphabet to some new one.
Having said that, there is no reason not to play with alternatives here.
That is surely the main advantage of the method advocated herein.
There is no cost in trying out new alphabets – in marked contrast to the cost and commitment required to empirical testing.
It is evident in Figure 11 that the most serious potential confusions are between digits,
two and three and between Mike and five.
As concluded above, though, it seems unlikely that any other words could be used, so in this experiment
(following the example of much of the literature)
we will not include the numbers.
Evidently (Figure 10) the weakest letters are Golf and Mike, which both have shortest distances of 2.
We start by finding potential replacements for them, bearing in mind the desirable characteristics listed above.
6.1 G
Possible candidates investigated were
Garlic
Gift
Glass
Gold
Glove
Galaxy
Goat
Gland
Words with a distance of 2 from any of the other words were rejected, namely those following, along with the words to which they were too close
Garlic – Alfa, Charlie
Gift – Alfa
Glass – Alfa
Gold – Echo
Glove – Alfa
The distances for the remaining words are shown in Figure 14.
As noted earlier, the easiest way to create a larger difference is to choose longer words, with more redundancy, so it is no surprise that Galaxy should show good distinctiveness.
Gland shows the next best figures.
However, with regard to the semantics of the word, it might be that some people would be uneasy, that they might think that such a biological word is inappropriate, that it might have obscene connotations
Letter
Galaxy
Goat
Gland
gæləksi
goʊt
glænd
A
Alfa
ælfə
5
4
4
B
Bravo
brɑvoʊ
7
6
6
C
Charlie
ʧɑrli
6
5
5
D
Delta
dɛltə
5
4
5
E
Echo
ɛkoʊ
7
3
5
F
Foxtrot
fɑkstrɑt
7
8
8
G
H
Hotel
hoʊtɛl
7
3
6
I
India
ɪndiə
6
5
5
J
Juliett
dʒuliet
7
7
7
K
Kilo
kɪloʊ
6
5
5
L
Lima
laɪmə
6
5
5
M
Mike
maɪk
7
4
5
N
November
noʊvɛmbər
9
7
8
O
Oscar
ɔskər
6
5
5
P
Papa
pɑpə
6
4
5
Q
Quebec
kwəbɛk
6
6
6
R
Romeo
roʊmioʊ
7
5
7
S
Sierra
siɛrə
6
5
5
T
Tango
tæŋgoʊ
6
6
5
U
Uniform
junəfɔrm
7
8
7
V
Victor
vɪktər
6
5
6
W
Whiskey
wɪski
7
5
5
X
X-ray
ɛksreɪ
7
6
6
Y
Yankee
jæŋki
6
5
4
Z
Zulu
zulu
6
4
3
Mean
6.44
5.10
5.10
Mode
6
4
5
Figure 14
Distances for the candidate alternative G-words.
Considering internationalization, French and Spanish translations are given in Table 4.
English
French
Spanish
Galaxy
galaxie
galaxia
Goat
chèvre
cabra
Gland
glande
glándula
Table 4
Candidate G-words in the three principal languages.
The fact that the French and Spanish words for Galaxy are quite similar, and that it would not have negative connotations in those languages suggest that it is the best candidate.
6.2 M
Candidate M-words were:
Mercury
Mole
Mud
Moon
Letter
Moon
Merc -ury
Mole
Mud
mun
mɜrkjəri
moʊl
mʌd
A
Alfa
ælfə
4
8
4
4
B
Bravo
brɑvoʊ
6
8
6
6
C
Charlie
ʧɑrli
5
7
4
5
D
Delta
dɛltə
5
8
4
4
E
Echo
ɛkoʊ
4
8
3
4
F
Foxtrot
fɑkstrɑt
8
7
8
8
G
Galaxy
gæləksi
7
8
4
7
H
Hotel
hoʊtɛl
6
8
4
6
I
India
ɪndiə
4
8
5
4
J
Juliett
dʒuliet
7
8
6
6
K
Kilo
kɪloʊ
5
8
4
5
L
Lima
laɪmə
5
7
5
5
M
N
November
noʊvɛmbər
8
9
7
9
O
Oscar
ɔskər
5
7
5
5
P
Papa
pɑpə
4
8
4
4
Q
Quebec
kwəbɛk
6
7
6
6
R
Romeo
roʊmioʊ
7
8
5
7
S
Sierra
siɛrə
5
7
5
5
T
Tango
tæŋgoʊ
6
8
6
6
U
Uniform
junəfɔrm
6
7
8
8
V
Victor
vɪktər
6
7
6
6
W
Whiskey
wɪski
5
7
5
5
X
X-ray
ɛksreɪ
6
7
6
6
Y
Yankee
jæŋki
5
7
5
5
Z
Zulu
zulu
3
8
4
4
Mean
5.52
7.60
5.16
5.60
Mode
5
8
4
6
Figure 15
Edit distances for the candidate alternative M-words.
English
French
Spanish
Mercury
Mercure
Mercurio
Mole
Taupe
Cabra
Moon
Lune
Luna
Mud
boue
lodo
Table 5.
Translations of the candidate M-words.
Note that although the French translation of the word for a mole animal is taupe, there is a word le môle, referring to a mole which is a breakwater.
Once again the longest suggestion, Mercury, shows the best distinguishability and is likely to be more familiar to non-native English speakers,
but as the longest it might be thought to slow down communication.
What happens if we make both of these substitutions?
Does another area of the child's ball pop out?
Not according to Figure 16.
Note that there are suddenly many more red cells in this table, marking more instances of the minimum edit distance,
but that distance is 3, not 2 as in Figure 10.
Figure 16
Edit distances for the suggested revised alphabet.
Overall median = 6. Largest distance = 9 (32 occurrences). Shortest distance = 3 (4 occurrences)
We have devised an alternative to the Nato alphabet that appears to be better, for it to be less likely to have confusion between pairs of letters.
For any practical implementation it would be appropriate to undertake empirical experiments to test reception in noise, as was done in the development of the ICAO alphabets.
However, it is important to repeat that it is most unlikely that the Nato alphabet will be replaced, even with a phonetically superior alternative.
7. Is it worth the bother?
A fair question to ask – and to address with the edit distance method – is whether it is worth the bother?
Are any of these alphabets better than just saying the letters in the normal way?
Figure 17 tests this, showing the edit distances between the normal pronumciations of the letters, Ay, Bee, Sea,
etc9.
Figure 17. Edit distances for the conventional pronunciation of letters.
Overall median = 2. Largest distance = 7 (48 occurrences). Shortest distance = 1 (80 occurrences)
According to this analysis, the conventional pronunciation is much worse.
There are 40 pairs with an edit distance of just 1 – which would be easily confused.
The only letter with a average distance is W (dʌbəlju), which is not a surprise as a longer, two-syllable word.
8. Summary
It would be convenient if there was a single metric by which alphabets could be compared, but there does not seem to be one.
The median edit distance is one guide.
However, that might conceal some problems.
For instance, the median might be large while one pair of letters could have a dangerously short edit distance.
Statistics for all the above alphabets are summarized in Table 6.
Of the remainder it is ITU which seems best:
It has the greatest overall median edit distance (8);
It has the largest distance (10), with 50 occurrences.
Its shortest edit distance is as big as 5, and only occurs 6 times.
It is also noticeable that the mean length of the IPA spellings is also the greatest, and perhaps this is all that is needed – the greatest number of phonemes and hence the greatest redundancy.
Recall, though, that this alphabet was rejected by the ICAO because
'the words were unsuitable because they were unusual in everyday language and because they lacked desirable phonetic qualities'
(ICAO, 1959, p.9).
Given that the words are all the names of cities and countries it is not clear why they were considered 'unusual'.
It might be that the names of cities in different countries are pronounced differently in different languages.
For instance, an Italian would refer to their home country as 'Italia' and would find it difficult to revert to the English pronunciation.
It is not, however, clear what 'phonetic qualities' are missing and in fact our analysis suggests the contrary.
The point is that possible auditory confusion is not the only criterion to be considered.
Table 6.
Summary data for the main alphabets investigated.
These results would suggest that the ICAO/Nato alphabet is a good one.
They would suggest that Nato/Galaxy/Mercury is a better one, but then, as argued previously, it is never likely to be adopted.
9. Discussion and Conclusions
The need for unambiguous verbal communication The history of the development and evolution of the Nato spelling alphabet is a rich one, which has only been sketched herein.
The main motivation behind this paper was to see whether measuring edit distances of phonetic spelling was a way of assessing the suitability of different spelling alphabets.
On that level the results are mixed.
The ICAO/Nato alphabet was derived on the basis of experiments into their auditory distinctiveness, but the results thereof do not agree very closely with this analysis.
(See in particular Figure 9).
So, it might be concluded that the method described herein is of little value.
On the other hand, perhaps it would be a useful quick-and-dirty method for pre-testing potential alphabets.
It is certainly much cheaper in time and money than embarking on making recordings (with different levels of noise) and testing them with a large number of participants.
If anyone were to attempt to devise another alphabet it would make sense to employ both the methods.
That is to say that a preliminary, low-cost evaluation could be carried out using edit distance and then further empirical test of listening to samples in noise carried out.
If this were to be done, though, the method ought to be rigorous, clearly documented and include an appropriate ststistical analysis.
It appears that a very simple rule-of-thumb for selecting an alphabet is just to measure the lengths of the words.
At the same time, it seems unlikely that anyone will ever need or want to devise a new international spelling alphabet.
If one were needed this method might be used in its development.
Having devised a candidate it would presumably be necessary to carry out empirical tests.
One problem of devising an international alphabet is that it will be used by speakers of different native languages, who will inevitably speak with an accent.
An advantage of the edit distance method is that it could be used to test different accents.
Although toPhonetics.com only generates two accents, American and British, a skilled phonetician could hear the words spoken by speakers with different accents and transcribe them into IPA.
Then the edit distances could be measured.
Appendices
Appendix A: The International Phonetic Alphabet (IPA)
The IPA consists of symbols that can represent each sound (phoneme) in spoken languages.
Not every language includes every possible phoneme, so in the examples in this paper only a subset of the IPA symbols are used.
The figure below (borrowed from dictionary.com is a guide to the
pronunciation of the IPA symbols used.
Consonants
Vowels
/b/
boy, baby, rob
/æ/
apple, can, hat
/d/
do, ladder, bed
/eɪ/
aid, hate, day
/dʒ/
jump, budget, age
/ɑ/
arm, father, aha
/f/
food, offer, safe
/ɛər/
air, careful, wear
/g/
get, bigger, dog
/ɔ/
all, or, talk, lost, saw
/h/
happy, ahead
/aʊər/
hour
/k/
can, speaker, stick
/l/
let, follow, still
/ɛ/
ever, head, get
/m/
make, summer, time
/i/
eat, see, need
/n/
no, dinner, thin
/ɪər/
ear, hero, beer
/ŋ/
singer, think, long
/ər/
teacher, afterward, murderer
/p/
put, apple, cup
/ɜr/
early, bird, stirring
/r/
run, marry, far, store
/s/
sit, city, passing, face
/ɪ/
it, big, finishes
/ʃ/
she, station, push
/aɪ/
I, ice, hide, deny
/t/
top, better, cat
/aɪər/
fire, tired
/tʃ/
church, watching, nature, witch
/θ/
thirsty, nothing, math
/ɒ/
odd, hot, waffle
/ð/
this, mother, breathe
/oʊ/
owe, road, below
/v/
very, seven, love
/u/
ooze, food, soup, sue
/w/
wear, away
/ʊ/
good, book, put
/ʰw/
where, somewhat
/y/
yes, onion
/ɔɪ/
oil, choice, toy
/z/
zoo, easy, buzz
/aʊ/
out, loud, how
/ʒ/
measure, television, beige
/ʌ/
up, mother, mud
/ə/
about, animal, problem, circus
Figure A. A guide to IPA pronunciation.
Appendix B: Edit distances
As mentioned above, the edit distance is essentially the number of edit operations required to transform one string to another.
In the context of this paper, the longer the edit distance the better: the more dissimilar the two words and hence the greater their phonetic difference and the lower liklihood that one could be confused with the other when spoken.
An edit operation is either
deletion
insertion, or
substitution
Examples
coffee & toffee
Edit distance = 1
The example in the paper was coffee and toffee which has an edit distance of 1: the substitution of c with t.
kitten & sitting
Edit distance = 3
This is calculated as follows
Source letter
Target letter
Operation
Operation cost
Total cost
New 'word'
k
s
substitution
1
1
sitten
i
i
no operation
0
1
sitten
t
t
no operation
0
1
sitten
t
t
no operation
0
1
sitten
e
i
substitution
1
2
sittin
n
n
no operation
0
2
sittin
g
insertion
1
3
sitting
This is reminiscent of the word ladder game, in which you transform one word into another, by making substitutions, although the added constraint in the game is that the intermediate steps must be recognized words.
B
O
O
T
S
O
O
T
S
H
O
T
S
H
O
E
Figure B.
Steps in a word-ladder game.
The edit distance between BOOT and SHOE is 3, but all the operations have to be substitutions.
Recall there is the added constraint in the game that the intermediate strings must also be recognized words
(unlike, for instance, sitten,above).
Be aware that the examples in this appendix are all words spelled in the conventional Latin alphabet, but the paper is about edit distances for strings of IPA symbols.
Schmidt-Nielsen, A (1987)
Intelligibility of ICAO Spelling Alphabet Words and Digits Using Severely Degraded Speech Communication Systems. Part I Narrowband Digital Speech,
Naval Research Laboratory, NRL Report 9035.
Footnotes
*
This is version 2.1 of this paper.
I released version 1 (unnumbered) on 9 April 2021, but then I had some additional thoughts.
I added the appendices, added to the section on Comparison with ICAO Experiments and
updated the Discussion and Conclusions.
Version 2.1 is dated 6 March 2024 and inludes a different handling of some statistics as well as some corrections.
1
'Spelling alphabets' are commonly referred to as 'phonetic alphabets'.
Indeed, the principal one that we discuss in this paper is officially called the Nato Phonetic Alphabet.
However, that name can be considered inaccurate in that phonetics are not really involved, and particularly in the context of a paper like this in which true phonetics are important, it would be confusing to use the term.
2Nato is an acronym, a word made of the initial letters of a number of component words, in this case
North
Atlantic
Treaty
Organization.
Many writers feel obliged to spell out such acronyms using capital letters.
I do not.
As long as the word formed is pronounceable and is used in that way, then it should be treated as any other name, regardless of its etymology.
After all, who would write RADAR (RAdio Detection And Ranging)?
This is not the same as an initialism, a word constructed from inital letters, but one which is not pronounceable, is spoken letter-by-letter and should be written in capitals (e.g. USA).
3ICAO (1959) is a military technical report from the Armed Services Technical Information Agency,
released under a Freedom of Information request in 2011.
The version released is a poor quality scan which is illegible in parts, and thus some of the information from it reported herein may be inaccurate.
4
George Bernard-Shaw made this point by suggesting that the word 'fish' might be spelt 'ghoti', if you take 'gh' from 'enough', 'o' from 'women' and 'ti' from 'station'.
Another example is the differences between the words 'bough', 'borough' and 'through'.
5
Note that occurrences of minimum and maximum lengths are double counted.
That is (for instance) if the distance between Alfa and Golf is 3, then the distance between Golf and Alfa is also 3.
This makes sense, though, in that if 'Alfa' can be confused for 'Golf', then 'Golf' can be confused for 'Alfa'.
6
British people – particularly those from Wales, Scotland and Northern Ireland, often balk at the fact that some people from other countries seem to assume that Britain and England are identical.
Perhaps the identification of a 'British accent' is one attempt to redress this error, but sadly this is misguided.
There is no British accent.
Certainly the way an Aberdonian speaks is very different from someone from London.
Yet it would not be correct to label an accent as English.
Again, a Geordie accent is very different from, say, a Birmingham one.
There has been the concept of Received Pronunciation.
It is not very clear from whom this accent was received, but it is probably best identified as the accent that was broadcast by the BBC in the 1950s and 1960s.
It was probably best identified with the middle-classes from the south-east of England.
It is the accent that you would have expected to hear on the BBC in the 1950s and 1960s;
'regional' accents were certainly not broadcast.
7
The spelling of Whiskey follows the American and Irish convention; a Scot drinks Whisky.
8
The number 0 is a relatively recent addition to mathematics.
It is unusual in that it is known by a various different names: zero, nought and oh, for instance.
The word Zero is phonetically distinct which made it a good candidate for the Nato alphabet, but the name is not a neologism, as might be assumed, the
first-known occurrence of it in English dating back to 1598, according to the OED.
9
Consistently with the rest of this paper, the American pronunciation of the letter Z ('Zee' or zi) has been used, in preference to the British 'Zed'.